UDP 통신이란?
- User Datagram Protocol, 데이터를 데이터그램 단위로 처리하는 프로토콜
- 비연결형, 신뢰성 없는 전송 프로토콜
- 데이터그램 단위로 쪼개면서 전송해야 하기 때문에 L4, transport Layer
TCP와 UDP가 나온 이유
- IP의 역할은 Host to Host만을 지원한다. 하나의 장비 안에서 수많은 프로그램이 통신해야 할 경우는 IP만으로는 한계가 있다
- =>프로세스별 구분 지을 수 있는 Port 번호가 등장하게 됨
- IP에서 오류가 발생하면 ICMP에서 알려준다. 하지만 알려주기만 할 뿐 대처는 못하므로 상위 프로토콜인 TCP와 UDP가 나오게 됐다
ICMP ? 인터넷 제어 메시지 프로토콜. 네트워크 컴퓨터 위에서 돌아가는 OS에서 오류 메시지를 전송받는데 쓰임
TCP와 UDP의 오류 해결법?
- TCP: 데이터의 순차성과 분실, 중복 등을 자동으로 보정해줌으로써 송수신 데이터의 정확한 전달을 보장
- UDP: IP가 제공하는 정도의 수준만을 제공하는 간단한 IP 상위 계층의 프로토콜, 확인 응답을 못하므로 TCP와 달리 에러가 날 수 있고 재전송이나 순서가 뒤바뀔 수 있는 번거로움 존재하며 신뢰도 떨어짐
UDP Header

- Source Port: 시작 포트
- Destination Port: 목적지 포트
- Length: 길이
- Checksum: 오류 검출
- 중복 검사의 한 형태로, 오류 정정을 통해 자료의 무결성을 보호하는 단순한 방법
UDP는 왜 사용할까?
- 데이터의 빠른 처리, 신속성 때문 !!
- 주로 실시간 방송과 온라인 게임에서 사용됨
- 네트워크 환경이 안 좋을 때, 끊기는 현상을 생각하자
DNS에서 UDP를 사용하는 이유
- DNS Request의 양이 작음 -> UDP Segment에 담길 수 있음
- 3 way handshaking으로 연결을 유지할 필요가 없음 (TCP는 Protocol Overhead가 큼 )
- Request의 손실은 Application layer에서 제어함으로써 신뢰성이 추가될 수 있음 (Timeout이나 재전송 작업을 통해서)
- DNS: port 53번
- 하지만 TCP를 사용하는 경우?
- Zone Transfer(=DNS 서버 간의 요청을 주고받을 때 사용하는 transter)를 사용해야 하는 경우!
- 데이터의 크기가 512바이트(UDP의 제한크기) 를 넘기거나 응답을 못받은 경우
TCP와 UDP 통신 실습
- UDP
UDP server 코드
from socket import *
serverName = "192.168.0.108"
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
serverSocket.bind((serverName, serverPort)) # 12000 포트로 들어오는 프로세스를 소켓에 바인딩
print("The server is ready to receive")
while True:
message, clientAddress = serverSocket.recvfrom(2048) # 서버에 들어온 정보를 2kbyte로 계속 읽어들임
modifiedMessages = message.decode().upper() # 읽어드린 바이트 정보를 str로 변환 후 대문자화
serverSocket.sendto(modifiedMessages.encode(), clientAddress) # 클라이언트 목적지 주소도 명시해서 보냄UDP client 코드
from socket import *
serverName = "192.168.0.108"
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_DGRAM) # UDP의 소켓타입=SOCK_DRGAM
message = input("input lowercase sentence")
clientSocket.sendto(message.encode(), (serverName, serverPort)) # 서버의 IP 주소와 port 번호를 명시해서 서버에게 데이터 요청
modifiedMessage, serverAddress = clientSocket.recvfrom(2048)
print(modifiedMessage.decode())
clientSocket.close()결과
- UDP는 비연결형 프로토콜로, 데이터 전송 시에 IP 주소와 port 번호를 명시해줘야 한다.
- sendTo() 메서드를 사용
- TCP
TCP server 코드
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_STREAM)
serverSocket.bind(("", serverPort))
serverSocket.listen(1)
print("The server is ready to receive")
while True:
connectionSocket, addr = serverSocket.accept() # 요청을 기다리고 받은 후엔 connection 소켓이라는 새로운 분리된 연결을 만듬
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode()) # UDP와 달리 connection이 있으므로 목적지 주소가 필요없음
connectionSocket.close() # 이때 serverSocket은 닫지 않음TCP client 코드
from socket import *
serverName = "192.168.0.108"
serverPort = 12000
clientSocket = socket(AF_INET, SOCK_STREAM) # TCP의 소켓타입=SOCK_STREAM
clientSocket.connect((serverName, serverPort))
sentence = input("Input lowercase sentence")
clientSocket.send(sentence.encode()) # 서버의 목적지 주소 명시안해도 됨
modifiedSentence = clientSocket.recv(1024)
print("From Server: ", modifiedSentence.decode())
clientSocket.close()결과
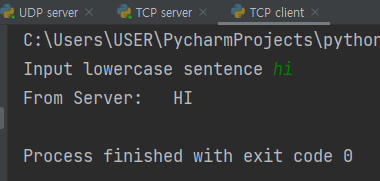
- TCP는 연결형 프로토콜로, 서버와 클라이언트는 항상 1대1로 연결되어서 통신하므로 따로 명시해줄 필요가 없다.
- send() 메서드를 사용
참고
'CS 공부 > 네트워크' 카테고리의 다른 글
| [네트워크] 17. Wireshark의 내부구조와 작동원리 (0) | 2023.01.10 |
|---|---|
| [네트워크] 16. IP헤더 형식과 의미 요약 (0) | 2023.01.09 |
| [네트워크] 15. L2 스위치에 대해서 (1) | 2023.01.08 |
| [네트워크] 14. 패킷의 생성 원리와 캡슐화 (1) | 2023.01.08 |
| [네트워크] TCP/IP (흐름제어/혼잡제어) (0) | 2023.01.07 |